Chapter 1 - Reliable, Scalable, and Maintainable Applications
Applications are either data-intensive or compute-intensive
An application is compute-intensive if the CPU is the limiting factor. It is data-intensive if the challenge it faces is volume, complexity, or the speed the data changes.
What are the elements that make a typical data-intensive application?
- Database for storage
- Cache for performance
- Search indexes
- Message queues
- Batch processing
What makes an application Reliable
A reliable application tolerates faults from its unreliable parts - hardware failure, software errors, human error; thru replication or by providing a degraded response.
What makes an application Scalable
A scalable application can cope with spikes in load within the agreed (SLA) response time using a measurable parameter such as requests per second, reads per second, or writes per second.
What makes an application Maintainable
In essence a maintainable application makes it easy for the team to get insight about the system and the ease at which new members get onboard and how hard it is to make a change.
CHAPTER 2 Data Models and Query Languages
Document Model and Relational Model
Schema-less label on Document Model databases are misleading.
- Document Model refers to NoSql databases. Their schema is enforced when data is read (schema-on-read). Preferred if you’re dealing with only one-to-many data.
- Relational Model refers to traditional SQL databases. Their schema is enforced before data is written (schema-on-write). Preferred if you’re dealing with a lot of many-to-many data.
Declarative and Imperative code
Data can be queried these days using declarative or imperative code.
- Declarative code - think SQL, XPATH, CSS selectors. You define the data you want and let the data store figure out how to retrieve it.
- Imperative code - given a data source, you write your own methods of traversing the model
Handling complex many-to-many relationships
When relationships become too complex for native foreign keys to address, one can use graph models. In a graph, data is referred as a vertice and the relationships as edges. In a social networking site every member is a vertice and its connection to another user is the edge. In the given book example 2 tables were created - 1 for the vertices and 2 for the edges. The primary keys in both tables can be used inside your entity tables instead of the traditional Foreign Key approach.
CREATE TABLE vertices (
vertex_id integer PRIMARY KEY,
properties json
);
/* head_vertex is where the relationship starts */
/* tail_vertex is where the relationship ends */
CREATE TABLE edges (
edge_id
integer PRIMARY KEY,
tail_vertex integer REFERENCES vertices (vertex_id),
head_vertex integer REFERENCES vertices (vertex_id),
label
text,
properties json
);
CREATE INDEX edges_tails ON edges (tail_vertex);
CREATE INDEX edges_heads ON edges (head_vertex);A similar concept to graph model is the triple-sore model. In this structure a line of data is arranged in 3 parts - subject, predicate, and object. A simple data might look like john,age,25. SPARQL (sparkle) is the given query language example that uses this approach.
CHAPTER 3 Storage and Retrieval
Clustered and non-clustered index
A clustered index is where a row is stored together with the index. Primary keys are clustered index. A non-clustered index is where only a reference to the data is stored alongside the index.
Disk-based vs in-memory database
In general disk-based storage, typically associated with relational databases, are read and written on disks while in-memory storage like memcache are read and written in RAM. Disk-based stores are more durable because they can be backed up and restored easily. In-memory stores have limited storage capacity and are less durable because they tend to lose their data when the machine restarts. It’s advantage lies in performance - your reads and writes are faster since everything is already in memory.
The technical implementation of disk-based and in-memory stores however blur the lines of their definition. Relational databases often have a in-memory caching layer for reads. Redis as an in-memory database writes data to the disk asynchronously every 2 seconds.
Choosing the right storage comes down to features you need. Disk-based is well-suited for data-at-rest because disk space capacity is higher and the availability of its querying language and replication features. Choose in-memory storage because of its speed and simple key-value structure which are great for caching strategies.
OLTP OLAP ETL and Data Warehousing
Online Transaction Processing (OLTP) are atomic transactional reads and writes mostly used in applications. Online Analytics Processing (OLAP) are queries that typically require a combination of huge datasets for the purpose of business intelligence (BI). Large business typically have 1 database for OLTP where data is periodically synced to a second database dedicated for OLAP through the process of Extract Transform Load (ETL). The separation between OLTP and OLAP is purely performance driven. The OLAP database is the Data Warehouse business people can use at their hearts content without affecting the OLTP database.
CHAPTER 4 - Encoding and Evolution
What is encoding
When dealing with data in a file (XML, CSV, JSON, YAML), data have 2 representations in an application - (1) for in-memory usually represented by objects, data structures and so on and (2) as a sequence of bytes. The process of transformation from 1 representation to the next is called encoding, sometimes serialization or marshalling.
CHAPTER 5 Replication
Reasons for replication
- To increase availability of data in case of a failure
- To reduce latency by placing the replica in a geographic location close to a set of users
- Backups
- Scalability when load increases
Synchronous and Asynchronous Replication Strategy
Synchronous replication is when subsequent operations are blocked until the write operation has been completed on the leader (master) and the follower (slave). You can set up 1 synchronous and 1 asynchronous replica. If the synchronous replica fails, you can promote the asynchronous replica to synchronous. This ensures that you have at least 2 up-to-date nodes in a given time.
Eventual Consistency
Eventual consistency is a characteristic of a replica in a leader-based architecture where a follower’s data doesn’t match its leader for a period of time because of a replication lag. It eventually catches up once the write process on the leader stops and the changes propagate to the followers.
Some strategies dealing with replication Lag
- Read-after-write - after performing a write operation, issue reads on the same machine where data was written
- Monotonic reads - read queries are time-based and sessions stick on the same machine the user first started on
Multi-Leader Replication Topologies
- Circular - writes follow a sequence
- Star / Tree - Leader 1 writes to Leader 2 which then writes to other followers
- All to All - allows writes to travel on any path
Leaderless replication
Writes are done on all replicas and a quorum is in place to determine how many successful writes out of the available replication nodes qualify for a success response. Reads are also issued on all the replicas using the same quorum to determine success. If at one point a write fails in any node, the next read will issue a write statement after the read command to keep the changes in sync (Read repair). The quorum is usually writes (w) + reads (r) > nodes (n). n is typically an odd number. w and r is the rounded value of (n+1) / 2. For 3n, you should have a sum of 4 for w+r to guarantee an up-to-date response.
CHAPTER 6 Partitioning
Partitioning (Sharding) for Scalability
For applications that have a high throughput, partitioning data is a helpful strategy for the system to cope with demand. If you have 3 partitions, it should be able to handle 3X as much data than a single partition. The main goals are to spread data and load evenly.
Avoiding partitions with higher loads (aka hot spot)
- Partition by Key Range - setting min and max values per partition to establish boundaries. This preserves the sort order but has lower distribution.
- Partition by Hash Key - A hashing algorithm is applied to the data and the records are stored based on the hash key range. This has better distribution than Key Range but you lose the sort order of your data. You can use a compound key in your table to work around the sort issue. Your first key is the hash, and the second the value of data you want to sort.
Storing Secondary Indexes (Foreign Key records) on Partitions
- By Document - data is most likely to be duplicated across partitions unless special care is given to avoid it. If you query records by a tag, it has to be issued across all the partitions then combined.
- By Term - data is stored in a single node making reads faster but writes more expensive. It also creates a bottleneck. It can however be partitioned as well.
Rebalancing partitions
Over time data sets or throughputs increase requiring you to add new partitions or nodes to handle the load. You will also need to rebalance your partitions. These are some strategies you can use
- Fixed number of Partitions - each node has a fixed number of partitions, say 5. When a new node is added, it grabs 1 partition from other nodes, lowering each node partition to 4.
- Dynamic partitioning - letting you datastore decide how it handles partitioning and allow it to adapt to your volume of data
- Partitioning proportionally to nodes - each node has a predefined number of partition
How will your application know that a new partition has been added?
In general this requires you to have a service discovery layer. The most common software used is ZooKeeper. Every new node added is registered and it exposes it to the routing layer for the application to use.
CHAPTER 7 Transactions
ACID Guarantees of a Transaction
- Atomic - a write is a sequence of commands and a failure of one means a failure of all
- Consistent - Table dependencies are in sync
- Isolated - One user’s write will not overlap with another
- Durable - Data is written on all nodes
Loss of Data Scenarios from a Race Condition in a Transaction
- Dirty write - newer change does not see uncommitted changes
- Lost update - overwriting another user’s changes
- Write Skew and Phantoms - multiple write operations happen at almost the same time causing you to violate your application rules. This is common in cases where a SELECT is issued before an INSERT, DELETE/DROP or UPDATE.
Weak Isolation levels that are used in practice by databases These are labeled “weak” because they do not fully guard against concurrency issues. They prevent returning bad data during a read operation with a concurrent write.
- Read committed - ensures that there are no dirty-read nor dirty-write. No Dirty read guarantees that only committed data are exposed. No Dirty Write guarantees that if an executed write operation is part of transaction, subsequent writes are to wait until the first write has been committed.
- Snapshot isolation - Helpful for long running read-only queries and back ups. readers never block writers, and writers never block readers. The database will only perform the read operation from a specific point in time. This works because the database maintains versions of committed values and will use those to prevent blocking write operations while the long-running process is taking place.
Preventing lost/overwritten updates during a race condition using Compare-and-set
Before executing an update, check if the value you’re updating has been changed. Error out if it has and retry again using the most current value. The query below will have no effect if someone else has updated the content column before yours was executed. This doesn’t work well with a replicated database especially in high traffic applications requiring fast throughput. In those cases, you often need to have application code that can mitigate the loss of data due to eventual consistency.
UPDATE wiki_pages SET content = 'new content'
WHERE id = 1234 AND content = 'old content';CHAPTER 8 The Trouble with Distributed Systems
Application Concerns to Plan for in Distributed Systems
- Unreliable networks
- Inaccurate clocks - machine clocks can drift and are almost never in sync
- Unexpected server timeouts - garbage collection, long running processes
Database Locks and Fencing tokens
Assume that your system utilizes locks with expiration on database records. Returning a “fencing token” is a strategy to guard against overwriting user2’s changes if user1’s request takes a long time to process. An incrementing fencing token is given to clients before any write. During submission the server will reject any request that is below the last stored token and accept only the ones above it.
CHAPTER 9 Consistency and Consensus
Creating a Consensus in a distributed system pp332
- Consensus Algorithms
- Leaderless
- Single Leader, where the leader is the single source of truth
- Multi-leader, where if 3 out of the 5 leaders agree on a fact, then it is indeed a fact
Generating database sequence numbers from multiple nodes
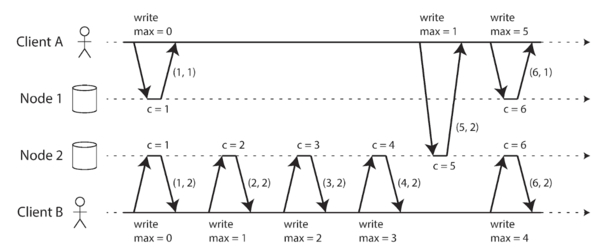
Some strategies for defining the sequence/ordering of operations on distributed systems are range allocation like 1M to 5M, even/odd, AM/PM timestamps. These however never guarantees it. A better way is to use Lamport timestamps - each node knows what the current max counter value is for other nodes. For every request, the counter value is submitted together with the node id. The counter is incremented irregardless of which node it originated. If 2 counter values are the same, the one one with the higher node Id wins.
ZooKeeper as a tool to determine consensus
“Tools like ZooKeeper play an important role in providing an “outsourced” consensus, failure detection, and membership (discovery) service that applications can use. It’s not easy to use, but it is much better than trying to develop your own algorithms that can withstand all the problems” of a distributed system
CHAPTER 10 Batch Processing
- Make each program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new “features”.
- Expect the output of every program to become the input to another, as yet unknown, program. Don’t clutter output with extraneous information. Avoid stringently columnar or binary input formats. Don’t insist on interactive input.
- Design and build software, even operating systems, to be tried early, ideally within weeks. Don’t hesitate to throw away the clumsy parts and rebuild them.
- Use tools in preference to unskilled help to lighten a programming task, even if you have to detour to build the
CHAPTER 11 Stream Processing
Stream as group of events (topic) incrementally made available over time
These events are captured through polling or message systems. If low latency is required, polling becomes expensive.
Messaging Systems
Messaging systems can be done brokerless (direct communication like UDP) or through a broker. The latter is needed when loss of data is unacceptable. Brokered systems address this by having an intermediary that can store or queue events from the source. The client connects to the intermediary and not the source. Software examples are RabbitMQ, ActiveMQ, MSMQ but log-based brokers can also be used.
CHAPTER 12 The Future of Data Systems
Making transactions idempotent through duplicate suppression
- POST-Redirect-GET
- Every transaction has an ID and the data store checks that that ID hasn’t been processed yet